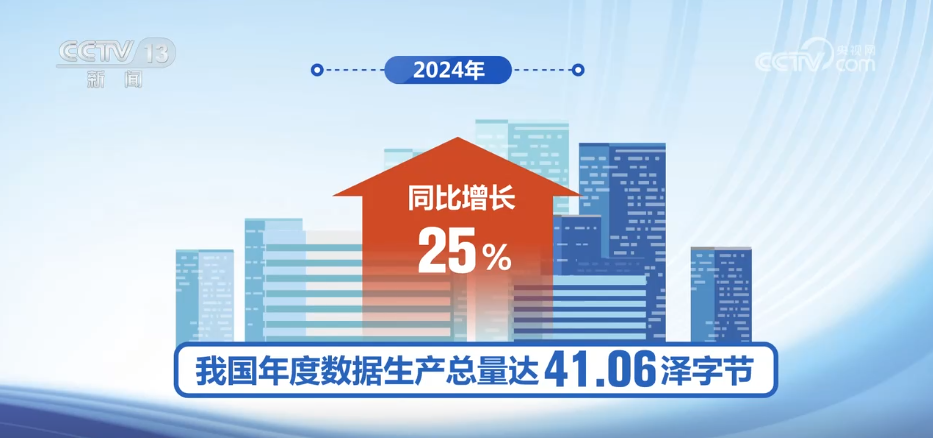
CCTV -Nachrichten: Am 17. Mai erfuhr der Reporter aus der Konferenz für Datensicherheitsentwicklung 2025, dass mein Land eine Reihe von vorgelagerten und nachgelagerten Unternehmen in der Branchenkette der Datenfaktor -Industrie kultivieren und erweitern wird. Es wird geschätzt, dass bis 2030 die Umfang der Datenindustrie meines Landes 7,5 Billionen Yuan erreichen wird.

Liu Liebong, Direktor der nationalen Datenverwaltung, sagte, dass er derzeit plant, ein horizontales, vertikales und koordiniertes und starkes Dateninfrastruktursystem zu erstellen und im Grunde genommen die Hauptstruktur der nationalen Dateninfrastruktur bis 2029 zu erstellen. src = "http://www.china-news-online.com/2025-05-18/1kqbamcvbsw.png" Alt = "" //
Die offene Freigabe der öffentlichen Daten ist zu einem wichtigen Unterbrecher bei der Vermarktung von Datenelementen geworden. Im Jahr 2024 stieg die Anzahl lokaler öffentlicher Daten offener Plattformen auf oder über dem kommunalen Niveau landesweit um 7,5%, die Anzahl der offenen Daten stieg um 7,1%und die Anzahl der hochwertigen Datensätze stieg gegenüber dem Vorjahr um 27,4%. In Bezug auf die Integration von Datenelementen und -industrien beschleunigt das Land die Eröffnungshindernisse für den öffentlichen Datenaustausch, fördert die tiefe Integration öffentlicher Daten und Unternehmensdaten und aktiviert eine massive "Schlafdaten".
Konstruktion hochwertiger Datensätze zur Beschleunigung der Entwicklung künstlicher Intelligenz. Hochwertige Datensätze sind nicht nur der Eckpfeiler des Sprung in der Leistung für künstliche Intelligenzmodelle, sondern auch die gesamte industrielle Kette von technologischer Forschung und Entwicklung bis zur kommerziellen Implementierung neu. Wie werden hochwertige Datensätze erstellt?

Technisches Personal teilte Reportern mit, dass das Erstellen großer Modelldatensätze hauptsächlich Kernverbindungen wie Datenerfassung, Datenreinigung, Datenanschlag und Qualitätsbewertung enthalten. Jeder Link muss gezielte technische Forschungen und Entwicklung und Anpassung auf der Grundlage der Merkmale der großen, ausreichenden Vielfalt und starken vertikalen Eigenschaften der Branche durchführen.
Datenanmerkungen und Reinigung sind wichtige Links zum Aufbau hochwertiger Datensätze. Die Datenannotation lehrt künstliche Intelligenz, die Welt zu "kognizieren", indem Sie "kennzeichnen" (z. B. Kennzeichnung von "Katzen" und "Hunden" für Fotos). Unbeschriebene Daten sind wie verstümmelte Lehrbücher, was dazu führt, dass künstliche Intelligenz effektiv gelernt wird. Die Datenreinigung reinigt Daten, indem sie Duplikate entfernen und Fehler korrigieren. Chaotische Daten beeinflussen direkt die Wirksamkeit des Trainings für künstliche Intelligenz.
Der Ausgangswert der Datenkennzeichnungsbranche meines Landes übersteigt 8 Milliarden
Es ist zu sehen, dass die Datenkennzeichnung ein Schlüsselbetrag bei der Konstruktion hochwertiger Datensätze ist. Was ist die Entwicklung der verwandten Industrien meines Landes? Der von der Konferenz 2025 Datensicherheitsentwicklung veröffentlichte "2025 hochwertige Datensatzbericht" veröffentlicht, dass mit der Iteration der künstlichen Intelligenz und der groß angelegten Modelltechnologie der Ausgangswert der Datenkennzeichnungsbranche meines Landes 8 Milliarden Yuan überschritten hat, und die Konstruktion hochwertiger Daten hat eine neue Phase der Groß- und standardisierten Entwicklung eingegeben.
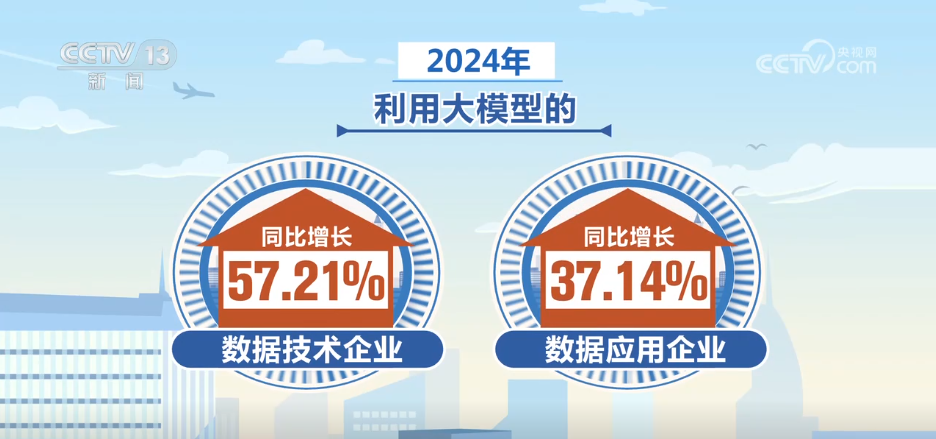
In 2024, the number of enterprises developing or applying artificial intelligence in my country increased by 36% gegenüber dem Vorjahr und die Anzahl der hochwertigen Datensätze stieg gegenüber dem Vorjahr um 27,4% und unterstützt künstliche Intelligenztraining und -anwendung stark. Datentechnologieunternehmen, die große Modelle und Datenanwendungsunternehmen verwenden, erhöhten sich um 57,21% bzw. 37,14% gegenüber dem Vorjahr.