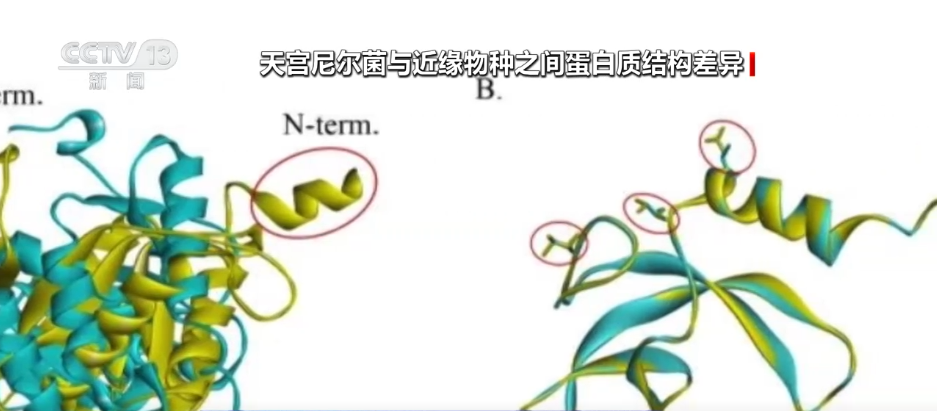
17 वें पर, रिपोर्टर ने 2025 डेटा सुरक्षा विकास सम्मेलन से सीखा कि मेरा देश डेटा फैक्टर उद्योग श्रृंखला में कई अपस्ट्रीम और डाउनस्ट्रीम उद्यमों की खेती और विस्तार करेगा। यह अनुमान है कि 2030 तक, मेरे देश के डेटा उद्योग का पैमाना 7.5 ट्रिलियन युआन तक पहुंच जाएगा।
सार्वजनिक डेटा का खुला साझाकरण
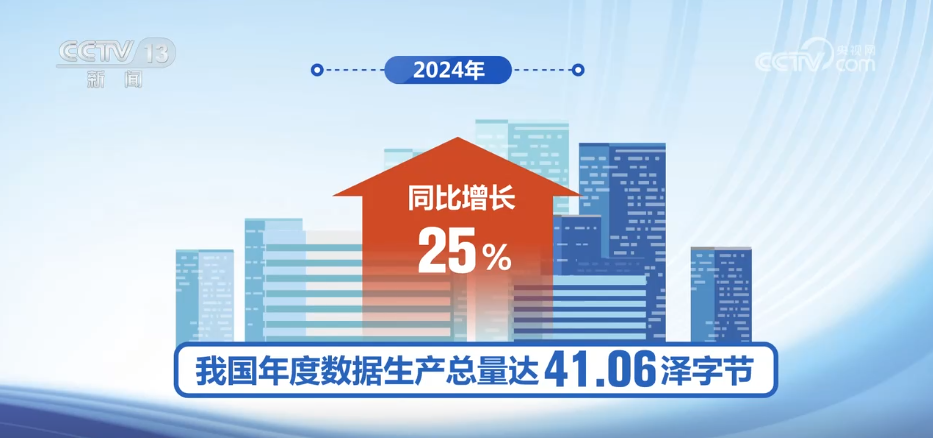
बड़े पैमाने पर "स्लीपिंग डेटा" को सक्रिय करें डेटा से पता चलता है कि 2024 में मेरे देश का वार्षिक डेटा उत्पादन 41.06 ज़ेट बाइट्स तक पहुंच गया, जो साल-दर-साल 25%की वृद्धि है।
अब तक, मेरे देश में डेटा क्षेत्र में 190,000 से अधिक संबंधित कंपनियां हैं, और डेटा उद्योग का पैमाना 2 ट्रिलियन युआन से अधिक है। 20%से अधिक की वार्षिक वृद्धि दर के आधार पर, मेरे देश के डेटा उद्योग का पैमाना 2030 में 7.5 ट्रिलियन युआन तक पहुंच जाएगा। Alt = ""/>
राष्ट्रीय डेटा प्रशासन के निदेशक लियू लेहोंग: वर्तमान में, हम एक क्षैतिज रूप से जुड़े, लंबवत रूप से जुड़े, और समन्वित डेटा इन्फ्रास्ट्रक्चर सिस्टम का निर्माण करने की योजना बना रहे हैं, और मूल रूप से 2029 तक राष्ट्रीय डेटा इन्फ्रास्ट्रक्चर की मुख्य संरचना का निर्माण करते हैं। src = "http://www.china-news-online.com/pic/2025-05-18/pudzsghxmjk.jpg" alt = "" //
सार्वजनिक डेटा का खुला साझाकरण डेटा तत्वों के विपणन में एक महत्वपूर्ण सफलता बन गई है। 2024 में, नगरपालिका स्तर पर या उससे ऊपर स्थानीय सार्वजनिक डेटा ओपन प्लेटफार्मों की संख्या में 7.5%की वृद्धि हुई, खुले डेटा की संख्या में 7.1%की वृद्धि हुई, और उच्च गुणवत्ता वाले डेटा सेटों की संख्या में 27.4%वर्ष-दर-वर्ष में वृद्धि हुई।
डेटा तत्वों और उद्योगों के एकीकरण के संदर्भ में, देश सार्वजनिक डेटा साझा करने के लिए उद्घाटन-अप बाधाओं को तेज कर रहा है, सार्वजनिक डेटा और उद्यम डेटा के गहरे एकीकरण को बढ़ावा दे रहा है, और एक बड़े पैमाने पर "नींद डेटा" को सक्रिय करता है।
उच्च गुणवत्ता वाले डेटा सेट का निर्माण करें
कृत्रिम बुद्धिमत्ता के विकास में तेजी लाएं उच्च गुणवत्ता वाले डेटा सेट न केवल कृत्रिम खुफिया मॉडल प्रदर्शन में लीप की आधारशिला हैं, बल्कि तकनीकी अनुसंधान और विकास से लेकर वाणिज्यिक कार्यान्वयन तक पूरी औद्योगिक श्रृंखला को भी फिर से आकार देते हैं। तो उच्च गुणवत्ता वाले डेटा सेट कैसे बनाए जाते हैं? डेटा तत्वों के राष्ट्रीय बाजार-उन्मुख सुधार के लिए "परीक्षण क्षेत्र" के रूप में, Wenzhou, Zhejiang में
एक डेटा सुरक्षा और अनुपालन प्रणाली को डेटा तत्वों के बड़े पैमाने पर प्रवाह सुनिश्चित करने, डेटा ट्रेडिंग पारिस्थितिकी तंत्र बनाने और अधिक डेटा "लाइव" बनाने के लिए यहां बनाया गया है।

तकनीकी कर्मियों ने संवाददाताओं को बताया कि बड़े मॉडल डेटा सेट का निर्माण मुख्य रूप से डेटा कलेक्शन, डेटा क्लीनिंग, डेटा एनलोटेशन, और क्वालिटी इवैलेंस शामिल है। प्रत्येक लिंक को लक्षित प्रौद्योगिकी अनुसंधान और विकास और अनुकूलन को बड़े पैमाने पर, पर्याप्त विविधता और उद्योग की मजबूत ऊर्ध्वाधर विशेषताओं के आधार पर करने की आवश्यकता है।

डेटा क्लीनिंग डुप्लिकेट को हटाकर और त्रुटियों को सही करके डेटा शुद्ध करता है, और अराजक डेटा सीधे कृत्रिम बुद्धिमत्ता प्रशिक्षण की प्रभावशीलता को प्रभावित करेगा।

मेरे देश के डेटा लेबलिंग उद्योग का आउटपुट मूल्य 8 बिलियन युआन
"2025 उच्च गुणवत्ता वाले डेटा सेट अनुसंधान रिपोर्ट" से अधिक है, जो 2025 डेटा सुरक्षा विकास सम्मेलन में जारी किया गया है, यह दर्शाता है कि आर्टिफिशियल इंटेलिजेंस और बड़े पैमाने पर मॉडल प्रौद्योगिकी के आउटपुट वैल्यू के साथ, माई कंट्रोलिंग के आउटपुट वैल्यू ने 8 बिलियन से अधिक कर दिया है। मानकीकृत विकास।
2024 में, मेरे देश में कृत्रिम बुद्धिमत्ता को विकसित करने या लागू करने वाले उद्यमों की संख्या में 36% वर्ष-दर-वर्ष वृद्धि हुई, और उच्च गुणवत्ता वाले डेटा सेटों की संख्या 27.4% वर्ष-दर-वर्ष बढ़ी, दृढ़ता से कृत्रिम खुफिया प्रशिक्षण और आवेदन का समर्थन करती है। बड़े मॉडल और डेटा एप्लिकेशन कंपनियों का उपयोग करने वाली डेटा प्रौद्योगिकी कंपनियों में क्रमशः वर्ष-दर-वर्ष 57.21% और 37.14% की वृद्धि हुई।
 </p> <!-repaste.body.end-> </div>
</div>
</section>
<div class=)